Dando continuidade as etapas do projeto de Data Science, mais precisamente a etapa dois (2) de coleta de dados - Colete Dados de todas as fontes para tal é necessário identificar qual a característica e identificar esse dado.
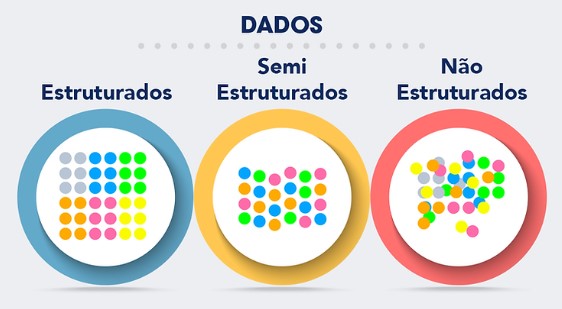
E no Universo da Ciência de Dados (Data Science), BI (Business Inteligence) e Big Data nós temos todos os tipos de dados e estes são: Dados Estruturados, Dados Semi Estruturados e Dados Não Estruturados.
Dados Estruturados: são rígidos e pré-definidos em modelos de dados que conhecemos como tabelas organizadas num SGBD (Sistema Gerenciador de Banco de Dados). Possui uma estrutura de relacionamentos e possui atributos de domínio específico ex. número, ou texto (fortemente tipados). São de fácil pesquisa e por fim, residem em Banco de Dados Relacionais e Data warehouses. Ex.: Banco de Dados.

Dados Semi Estruturados: possuem representação estrutural heterogênea, não podemos considerar completamente desestruturados, nem fortemente tipados. São auto-descritivos possuem um schema de representação associado ao dado. Ex.: XML, RDF, OWL.
Dados não estruturados: não possuem qualquer estrutura pré-definida, constituem a maioria dos dados corporativos e são a maior parte das informações da Web (cerca de 90%). São exemplos relatórios, documentos, imagens, áudios e vídeos. A Web em 1 minuto:
Links:
- Livros sobre Python
- Livros sobre Data Science
- Livros sobre Análise de Dados
- Livros sobre Business Inteligence
- Livros sobre Visualização de Dados
- Livros sobre Power Bi
- Livros sobre Tableau
- Livros sobre Qlik
- Livros sobre Data Mining
- Livros sobre Mineração de Dados
- Livros sobre Banco de Dados
- Livros sobre Estatística